
Tailored AI vs Generalist Models: A Federated Approach to Blood-Brain-Barrier Permeability
- Apr 30
- 5 min read
Updated: May 8
Qubigen’s recent study on tailored federated AI for blood-brain-barrier permeability prediction has now been featured by Diagnostics World News in an article exploring why specialized AI systems are outperforming generic foundation models in life sciences.
The feature highlights Qubigen’s findings that federated, client-adapted AI Engines can dramatically outperform generalist models when applied to real-world drug discovery datasets.
Below, we explore the full technical results behind the study.
In drug discovery, few challenges are as persistent and as costly as predicting whether a molecule will cross the blood-brain barrier (BBB) – a crucial property for central nervous system indications, but often a liability for others. It’s a problem that sits at the intersection of chemistry, biology, and data, and one that even state-of-the-art AI models struggle with.
At Qubigen, we investigated whether our AI Engine, tailored to client-specific data using our Federated AI platform, could outperform generalist models for predicting BBB permeability. We found that tailoring the Federated AI Engine using client-specific data led to a dramatic increase in accuracy on that dataset, without sacrificing performance on a standard benchmark dataset.
The Standard: A Strong Generalist AI Model
For this investigation, we compared performance of a state-of-the-art, generalist AI model [1] from Greenstone Biosciences and Stanford University to tailored AI Engines developed using Qubigen’s patented Federated AI approach. BBB permeability is a well-studied ADMET property with established public benchmarks, yet remains highly sensitive to experimental context, assay definition, and chemical series, making it an ideal test case for assessing the limitations of standard, generalist models on heterogenous datasets.
The dataset used for initial development of the generalist model was the publicly available Martins BBB dataset [2], consisting predominantly of approved drugs and other well-studied compounds. In this dataset, molecules are annotated with binary BBB permeability labels derived from a wide range of heterogeneous literature sources according to experimental evidence aggregated across multiple studies and experimental paradigms. It therefore represents a strong benchmark for evaluating model performance on generally representative BBB data.
Generalist AI Performance is Poor on Client-Specific Data
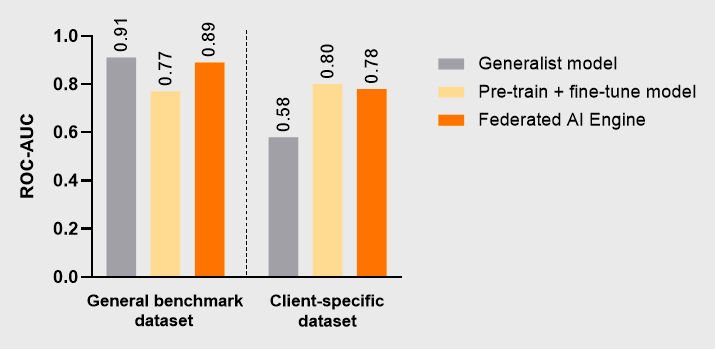
Performance of the generalist AI model on the original benchmark dataset was reported to be high, with AUC values close to 0.9 [1]. However, when the generalist model was applied to data representative of a typical a client-specific program, its performance dropped sharply. AUC values fell to 0.58, and more critically, the model exhibited extremely high false positive rates, predicting every compound as BBB-penetrant (specificity of 0%). This demonstrates how an AI model trained only on general, externally derived data can become highly unsuitable for evaluating program-specific, cutting-edge research compounds.
On the other hand, the client-specific dataset consisted primarily of earlier-stage research compounds, with BBB labels applied using quantitative pharmacokinetic measurements. This type of client program data likely captures a more realistic representation of use cases for predictive AI models. Our results showed that the generalist model does not translate effectively to different experimental and chemical landscapes, such as those found across divergent drug development programs.
Federated AI Achieves Both Specialization and Generalization
The Qubigen team then explored whether performance could be improved by taking the original generalist model and fine-tuning using client data – a method that can remain privacy-preserving through the benefits of Federated AI. These optimizations instantly increased accuracy on client-specific data by almost 40%, bringing the AUC up from 0.58 to 0.80. Importantly, the fine-tuned model was correctly identifying both positives and negatives with greater balance than the generalist model. However, there was a crucial limitation - this improvement was at the expense of accuracy on the original benchmark dataset, with AUC dropping from 0.91 to 0.77. Optimizing specifically for client-specific data therefore degraded performance on general data.
Next, we applied our Federated AI platform to bridge performance on both general and client data using multi-node training. Instead of pooling data into a single dataset, training a generalist AI model, or overwriting model knowledge through fine-tuning, we trained a new, multi-node Federated AI Engine optimized for client-specific datasets, with contributing datasets remaining on separate, privacy-preserving federated nodes. In this type of federated learning, knowledge is shared across decentralized nodes without exposing private data, allowing AI models to learn in a balanced way from distributed datasets. The resulting multi-node Federated AI Engine achieved high accuracy on the client-specific dataset, with an AUC of 0.78, whilst also retaining high performance on the benchmark dataset (AUC of 0.89).
These observations show that Qubigen’s AI Engine was effectively able to integrate complementary information relevant to BBB permeability from multiple datasets shaped by different experimental contexts, without overfitting to either dataset. It also shows how Qubigen’s Federated AI platform is uniquely situated for data node-orchestration, and selectively prioritizing distributed datasets without exposing them, to achieve a balanced outcome.
Why Tailored AI Matters for Drug Discovery
Generalist AI models, no matter how advanced, are inherently limited by the data they are trained on. They provide a static view of the world - one that may not align with the unique chemical series, assay formats, experimental conditions, or biological contexts of a given research program. In contrast, a tailored, federated approach allows models to adapt to client-specific considerations. By incorporating proprietary client data securely, without the need for data sharing, these models can learn the nuances that drive real-world outcomes.
This translates directly into better decision-making. Fewer false positives mean fewer wasted experiments. Better prioritization means more efficient use of resources. And critically, the ability to retain strong performance across multiple data contexts ensures that gains in one area do not come at the expense of another.
The Future of AI in Drug Discovery
Improved BBB prediction in this study is a broader reflection of how AI must evolve to meet the realities of modern drug discovery. As AI adoption accelerates, the industry must move beyond the idea of one-size-fits-all models. Performance gains in AI drug discovery are not only driven by model architecture, but by access to the right data for a given problem.
The future lies in tailored Federated AI Engines that adapt to the unique characteristics of each organization’s data while still benefiting from broader, public knowledge. Qubigen builds these Engines that can evolve with each program, learning from its unique data and continuously improving over time. Qubigen’s Federated AI platform allows clients to unlock the full value of their proprietary data, achieving measurable improvements in predictive performance, without compromising on data privacy and ownership.
 | Accelerate Drug Design Without Exposing Secrets |
Qubigen builds and hosts powerful, privacy-preserving AI Engines, turning discrete client-specific data into a competitive edge.
Whether you're advancing active programs, reviving dormant data, or starting from scratch, Qubigen’s secure Federated AI and quantum chemistry platform can help you identify, optimize, and accelerate the path to promising lead drug candidates. Get in touch to explore how we can support your next development.
References
[1] Swanson, K. et al. ADMET-AI: a machine learning ADMET platform for evaluation of large-scale chemical libraries. Bioinformatics 40, btae416 (2024).
[2] Martins, I. F., Teixeira, A. L., Pinheiro, L. & Falcao, A. O. A Bayesian approach to in silico blood-brain barrier penetration modeling. J. Chem. Inf. Model. 52, 1686–1697 (2012).


